

How to Create a Local LLM Using HuggingFace API Transformers and F#.NET



Keep smiling always. Coding is difficult? Smile more!
To create a local large language model using Hugging Face’s Transformers library and F#/.NET, you can follow these steps:
Install Required Packages:
Install the HuggingFace.Transfomers package from NuGet. You can use the Package Manager Console or the .NET CLI to install it:
dotnet add package HuggingFace.Transfomers
Install any additional packages you may need for your interactive interface, such as FSharp.Compiler.Service or Fable.
Load Pretrained Model:
Choose a pre-trained language model from the Hugging Face Model Hub. You can find various models trained on large datasets, such as GPT-2 or GPT-3.
The concept of using pre-trained language models is often referred to as transfer learning.
In your F# code, use the AutoModel class from the HuggingFace.Transfomers package to load the pre-trained model:
open Huggingface.Transfomers // Load the pretrained model let model = AutoModel.ForPretrainedModel("model_name")
Tokenization:
Tokenize the input text using the tokenizer associated with the loaded model:
// Load the corresponding tokenizer let tokenizer = AutoTokenizer.ForModel(model_name) // Tokenize the input text let input = "Your input text" let tokenizedInput = tokenizer.Encode(input)
Inference:
Feed the tokenized input to the loaded model for inference and obtain the model’s response:
// Inference let response = model.Forward(tokenizedInput)
Postprocessing:
Convert the model’s response back to human-readable text using the tokenizer.
// Decode the model's response let decodedResponse = tokenizer.Decode(response)
Interactive Interface:
Build your interactive interface using F# libraries like FSharp.Compiler.Service or Fable.
Handle user input and call the tokenization, inference, and postprocessing steps accordingly.
Display the model’s response to the user.
Here’s an example of an interactive F# console application that uses Hugging Face’s Transformers library to create a local language model:

We’re serious about HuggingFace. Especially the face!
open Huggingface.Transfomers
// Load the pretrained model
let model = AutoModel.ForPretrainedModel("model_name")// Load the corresponding tokenizer
let tokenizer = AutoTokenizer.ForModel("model_name")// Interactive loop
let rec interactiveLoop () =
printfn "Enter your input:"
let input = Console.ReadLine()
let tokenizedInput = tokenizer.Encode(input)
let response = model.Forward(tokenizedInput)
let decodedResponse = tokenizer.Decode(response)
printfn "Model response: %s" decodedResponse
interactiveLoop ()// Start the interactive loop
interactiveLoop ()
Remember to replace "model_name" with the actual name of the pre-trained model you want to use.
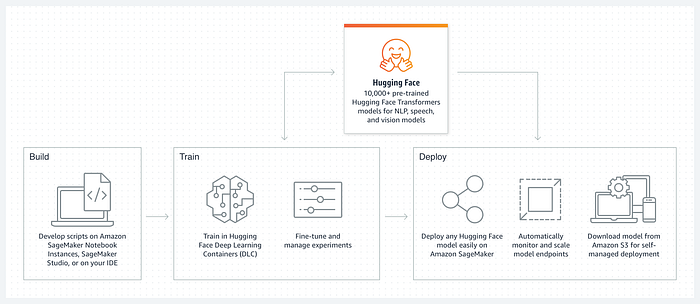
This entire process might run on your local system, but in case you want to really get into the whole business and ask some very open-ended questions to fully trained and optimized transformers, running the transformers on the cloud might be the best solution.
Amazon has created an interesting tool: Amazon SageMaker Studio which looks similar to a Jupyter Notebook but runs on the cloud. Make sure you estimate model costs, your own bank balance, and your current budget before you ever start with say, the BLOOM LLM (176 Billion parameters, FYI).
Budget or get broke very fast. Be careful! We’re paying in USD!
Summary
The code provided allows you to create a local large language model using Hugging Face’s Transformers library and F#/.NET. It works locally by loading the pre-trained model and tokenizer into memory and performing inference on the local machine.
However, it’s important to note that the size and complexity of large language models may require significant computational resources and memory. Therefore, depending on the specific model and hardware available on your local machine, you might encounter resource limitations when working with very large models.
If you’re working with a particularly large language model that exceeds the capabilities of your local machine, you may need to consider utilizing cloud resources, such as cloud-based GPUs or TPUs, to perform inference efficiently. Cloud platforms like Amazon Web Services (AWS), Google Cloud Platform (GCP), or Microsoft Azure offer services for running deep learning models at scale.

In such cases, you would typically deploy your F# code to the cloud platform of your choice and leverage the cloud’s computational resources to handle the model’s computation. Your local interface can then communicate with the deployed model via API calls or other integration methods.
The code provided can serve as a foundation for building the interactive interface and handling the communication with the model, regardless of whether it is executed locally or with cloud resources. The decision on where to run the model depends on the specific requirements, available resources, and scalability needs of your application.

These AI images Really Blew My Mind!
Code-Based HuggingFace API
From the HuggingFace website documentation:
If you need to create a repo from the command line:
$pip install huggingface_hub
#You already have it if you installed transformers or datasets
$huggingface-cli login
#Log in using a token from huggingface.co/settings/tokens
#Create a model or dataset repo from the CLI if needed
$huggingface-cli repo create repo_name --type {model, dataset, space}
Clone your model or dataset locally
#Make sure you have git-lfs installed
#(https://git-lfs.github.com)
$git lfs install
$git clone https://huggingface.co/username/repo_name
Then add, commit and push any file you want, including large files
# save files via `.save_pretrained()` or move them here
$git add .
$git commit -m "commit from $USER"
$git push
In most cases, if you’re using one of the compatible libraries, your repo will then be accessible from code, through its identifier: username/repo_name
For example for a transformers model, anyone can load it with:
tokenizer = AutoTokenizer.from_pretrained("username/repo_name")
model = AutoModel.from_pretrained("username/repo_name")
Surprisingly simpler and more accessible than one might think. That’s the true power of the HuggingFace API.
Or you can use the pipeline library, which does both tokenization and loading pre-trained weights (transfer learning).
Of course, we need to discuss the HuggingFace Hub:

As Imaginative As It Gets! All the world Is your stage!
The Hugging Face Hub
The Hub serves as a collaborative platform that aims to advance Machine Learning by fostering community-driven efforts. It provides a centralized space where individuals can easily share, explore, discover, and experiment with open-source Machine Learning resources, including models, datasets, and demos.
The Hub boasts an extensive collection of over 120,000 models, 20,000 datasets, and 50,000 demos. It serves as a hub for knowledge and resources, enabling researchers and developers to collaborate effectively. Emphasizing the importance of collective contributions, the Hugging Face Hub recognizes that no single company can solve the challenges of AI alone. Therefore, it promotes the sharing of knowledge and resources within a community-centric approach to democratize and advance Machine Learning for everyone.
The Hugging Face Hub is host to Git-based repositories, which provide version control and house various files. Through the Hub, users can upload and discover a wide range of resources, including:

Muzli Inspiration (From Medium)
Models
The Hub features the latest state-of-the-art models for NLP, vision, and audio tasks. Users can access thousands of open-source ML models contributed by the community. To ensure responsible model usage and development, model repositories are equipped with Model Cards that provide information about each model’s limitations and biases. Users can also include additional metadata, such as task information, languages, and metrics. If available, training metrics charts, including TensorBoard traces, can be added to the repository. Moreover, the Hub allows users to integrate inference widgets, enabling interactive model exploration directly in the browser. For production settings, an API is provided to facilitate instant model serving.

What the heck….!
Datasets
The Hub hosts over 5,000 datasets in more than 100 languages, catering to various NLP, Computer Vision, and Audio tasks. Finding, downloading, and uploading datasets is made simple through the Hub’s intuitive interface. Each dataset is accompanied by extensive documentation in the form of Dataset Cards and Dataset Previews, enabling users to explore the data directly in their browsers. While many datasets are publicly accessible, individuals and organizations can create private datasets to comply with licensing or privacy requirements. The Hub’s datasets library allows for programmatic interaction with the datasets, enabling seamless integration into projects. Even for large datasets that may not fit into local storage, streaming is supported to facilitate efficient data access.

A Whole New World…
In conclusion, the Hugging Face Hub stands as a testament to the democratic and open nature that AI should embody. By providing open-source and accessible resources, particularly through the Transformers library, Hugging Face empowers the ML community to explore, utilize, and contribute to the advancement of Machine Learning.
From https://huggingface.co/docs/hub/index
Finally:
I hope this has been an enlightening article. It is amazing what SOTA models can do these days. And with HuggingFace, nearly all of that functionality is open source and free to all communities.
Enjoy Transformers!
AWS for HuggingFace!